UTF8 to Base64URL Converter Guide
To convert UTF-8 to Base64URL as of May 2026, you need […]
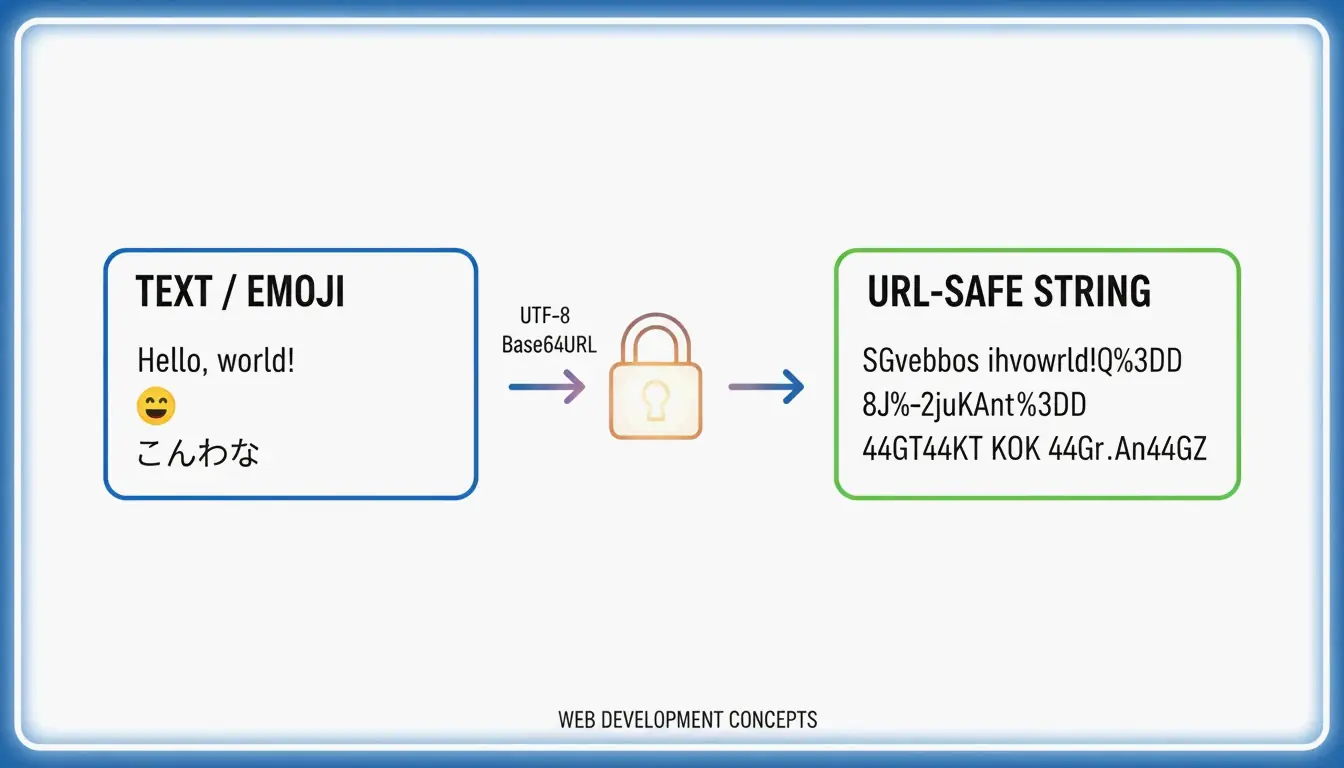
To convert UTF-8 to Base64URL as of May 2026, you need to encode your text into bytes, apply standard Base64, swap ‘+’ with ‘-‘, ‘/’ with ‘_’, and remove any trailing ‘=’ padding. This UTF-8 to Base64URL converter guide ensures your data remains URL-safe for JWTs and API headers according to RFC 4648 standards.
What is Base64URL and Why Does It Matter for UTF-8?
Base64URL is a specific version of Base64 encoding built for the web. Standard Base64 uses characters like the plus sign (+) and forward slash (/), which can break URLs or require extra “percent-encoding” (like turning a space into %20). Base64URL fixes this by using a hyphen (-) and an underscore (_) instead. This makes the encoded string safe to use directly in web addresses and filenames.
UTF-8 is the starting point for this whole process. It is the standard way the modern web handles text, allowing us to use everything from standard English letters to emojis and complex scripts. Before you can turn text into a Base64URL string, you must first convert that text into UTF-8 bytes. If you skip this step, special characters or emojis will likely break during the conversion.
As the NextUtils Team points out: “Base64 is an encoding scheme, not encryption.” It’s a tool for moving data through text-only channels, like HTTP headers or JSON files, without accidentally triggering system errors caused by hidden control characters.
The RFC 4648 Standard: Consistency in Modern Web Development
The RFC 4648 §5 specification defines the “Base 64 Encoding with URL and Filename Safe Alphabet.” This standard ensures that everyone follows the same rules. By sticking to RFC 4648, a developer can create a security token in Python on the backend and trust that a JavaScript frontend will decode it perfectly. It’s all about making sure different systems can talk to each other without losing data.

How to Convert UTF-8 to Base64URL: A Step-by-Step Framework
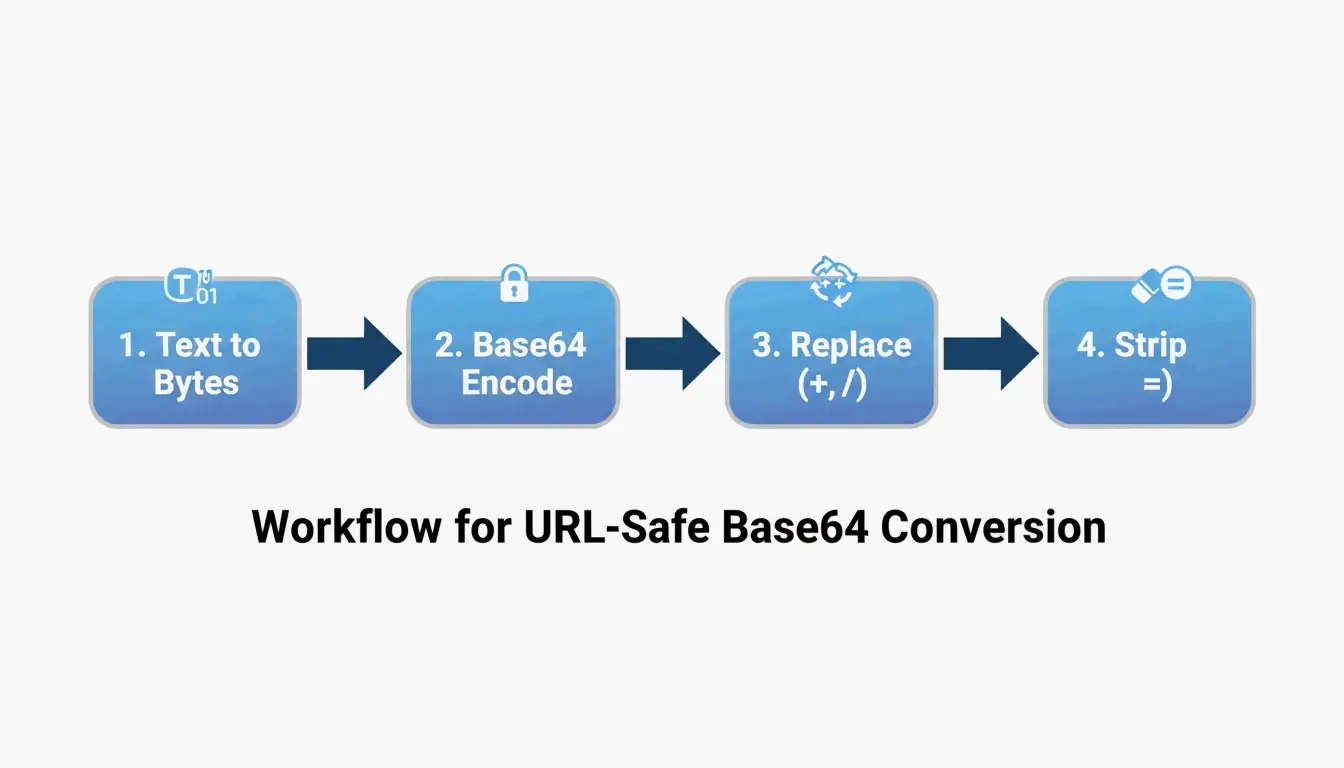
To get a clean result, follow these four steps in order. This prevents data loss, especially when your text includes emojis or non-English characters.
Step 1: Convert UTF-8 string to binary data
First, turn your readable text into a sequence of bytes. This is the most important step for supporting Unicode. If you try to use old methods like atob() directly on a string, you’ll often run into a TypeError or end up with garbled text when using emojis.
Step 2: Apply standard Base64 encoding
The binary data is grouped into 24-bit segments and mapped to the Base64 alphabet. According to Wikipedia, this process makes the data about 33% larger than the original binary version.
Step 3: Perform character substitution
Take your standard Base64 string and swap the characters that aren’t URL-friendly: change every + to - and every / to _.
Step 4: Handle the trailing Padding (=) character
Standard Base64 uses = at the end to make sure the string length is a multiple of four. In Base64URL and JWTs, we usually strip these out because the = character itself can cause issues in a URL.
Handling Unicode and Emojis Without Corruption
Modern apps handle much more than just plain English. To keep your data from breaking, you need a “Unicode-safe” approach. In 2026, the best practice is using the TextEncoder API. This ensures the string is treated as a series of UTF-8 “octets” (bytes). Without this, an emoji like 🌍 might turn into a mess of random symbols—a problem developers call “Mojibake.”
Implementation Guide: Modern Code Snippets (2026 Edition)
While the logic is the same across different programming languages, the way you write it changes depending on your environment.
Unicode-Safe JavaScript (Browser)
In a modern browser, use TextEncoder to handle the byte conversion correctly:
function toBase64Url(str) {
const bytes = new TextEncoder().encode(str);
const base64 = btoa(String.fromCharCode(...bytes));
return base64.replace(/\+/g, '-').replace(/\//g, '_').replace(/=+$/, '');
}
Python 3: Standard Library Approach
Python makes this easy with the base64 module. As AskPython notes, you should always handle your data as bytes:
import base64
data = "Hello 世界! 🌍"
# Encode to UTF-8 bytes, then to URL-safe Base64
encoded = base64.urlsafe_b64encode(data.encode('utf-8')).decode('utf-8').rstrip('=')
print(encoded)
Node.js: High-Performance Buffer Conversion
For backend APIs using Node.js, the Buffer object is the most efficient way to handle the transformation:
const str = "API_Payload_Data";
const base64url = Buffer.from(str, 'utf8')
.toString('base64')
.replace(/\+/g, '-')
.replace(/\//g, '_')
.replace(/=/g, '');
Troubleshooting: Fixing ‘Incorrect Padding’ and Malformed Input
A common headache happens when a decoder gets a Base64URL string without padding and throws an error like binascii.Error: Incorrect padding. To fix this, you need to add the = signs back until the string length is a multiple of 4. AskPython suggests calculating the missing padding using len(data) % 4 and appending the characters before you hit decode.
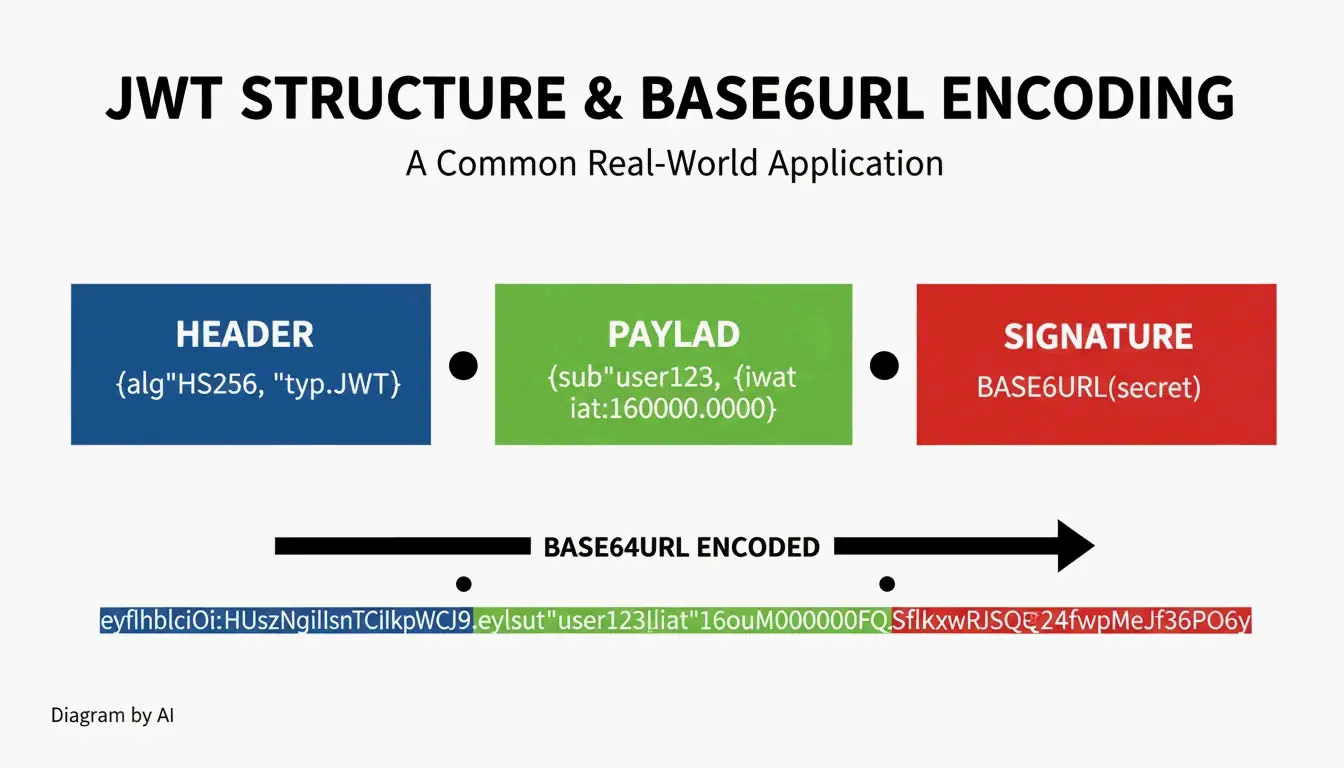
Base64URL in Action: JWTs and Data URIs
The most famous use for Base64URL is the JWT (JSON Web Token). These tokens have three parts (header, payload, and signature) separated by dots. Each part is encoded using Base64URL. This is why many tokens start with eyJ, which is just the Base64URL version of the opening JSON bracket {.
While Base64URL is the go-to for tokens, standard Base64 is still used for Data URIs and HTTP Basic Authentication. Data URIs let you embed images directly into your code using src="data:image/png;base64,...". This can speed up a site by reducing the number of files the browser has to download, but be careful: that 33% size increase can actually slow down your page if the files are too large.
Conclusion
Mastering the conversion from UTF-8 to Base64URL is essential for modern web development. It ensures that complex Unicode data stays intact when passed through APIs and JWTs. By following the RFC 4648 standard and the steps outlined above, you can avoid common issues like broken emojis or padding errors. For the best results, stick to the TextEncoder method in the browser and always ensure your backend and frontend are following the same RFC 4648 rules.
FAQ
Is Base64URL the same as encryption for securing sensitive data?
No, Base64URL is an encoding scheme, not encryption. It is a reversible process that anyone can undo without a secret key. Its only job is to make sure data can travel safely through text-based systems like URLs. For sensitive information, you must use actual encryption like AES-256 or secure protocols like TLS/SSL.
Why does my Base64URL string fail to decode in a standard Base64 decoder?
Standard Base64 decoders look for + and / characters and usually expect the = padding to be there. Since Base64URL uses - and _ and often removes the padding, a standard decoder will think the string is broken. You have to swap the characters back and restore the padding before using a basic decoder.
Why is the ‘=’ padding often omitted in Base64URL and JWT tokens?
The = character isn’t “URL-safe” and often has to be converted to %3D, which makes the string longer and harder to read in a web address. RFC 4648 allows developers to skip the padding in things like JWTs because the decoder can usually figure out the original length without those extra markers.
SectoJoy
• Indie Hacker & DeveloperI'm an indie hacker building iOS and web applications, with a focus on creating practical SaaS products. I specialize in AI SEO, constantly exploring how intelligent technologies can drive sustainable growth and efficiency.




