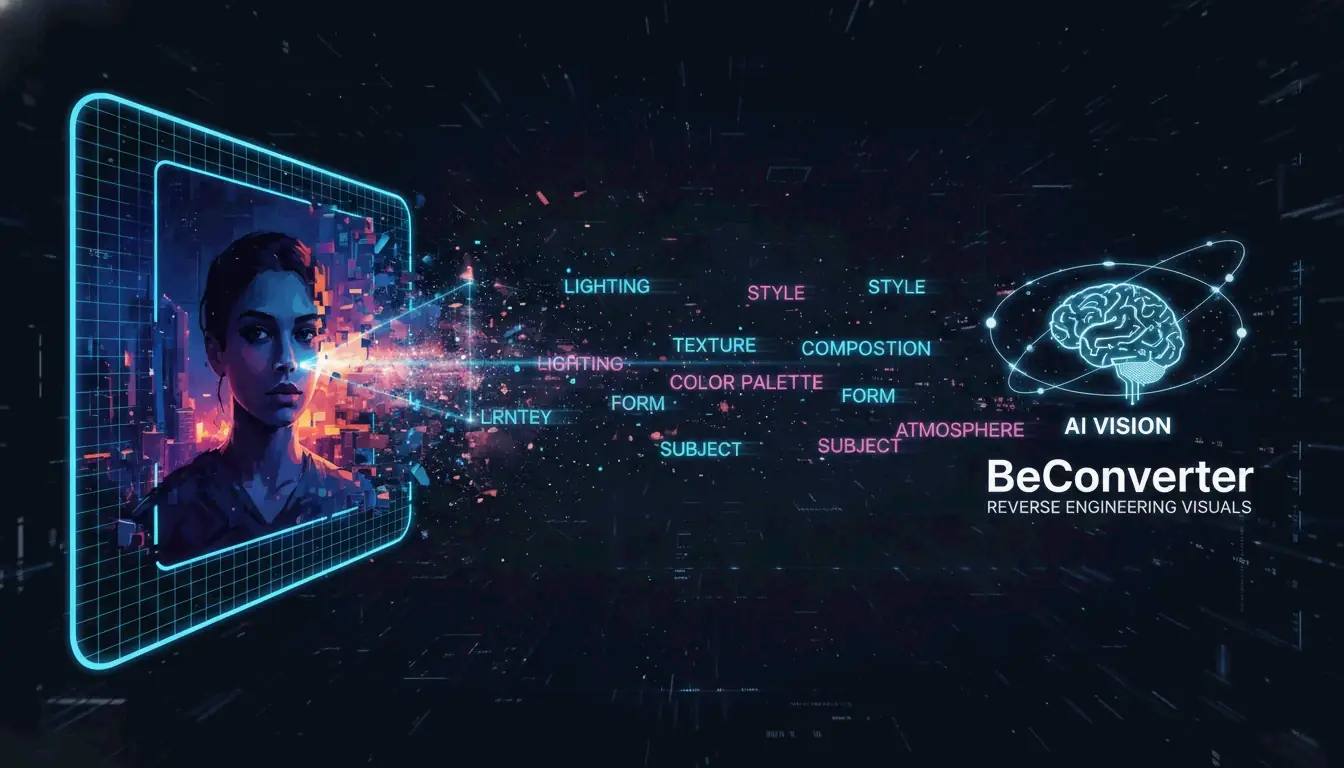
How to AI Prompt with BeConverter: A Complete Guide to Reverse Engineering Visuals
To master how to AI prompt with BeConverter and reverse […]
To master how to AI prompt with BeConverter and reverse engineer visuals, start by uploading your image to the platform to activate its Vision-Language Model (VLM). The AI breaks down the image into style tokens like lighting and composition to generate a descriptive text prompt. By May 2026, you can easily refine these results to recreate high-quality visuals in tools like Midjourney, Stable Diffusion, or FLUX.
What is Reverse Prompting and How Does BeConverter Work?
Reverse prompting is essentially the tech that turns visual pixels back into text that a machine can understand. Think of it as the opposite of a standard prompt. Usually, you start with an idea and ask the AI to draw it. With reverse engineering, you start with a finished image and work backward to find the “recipe”—the specific keywords, lighting settings, and aesthetic tags that made it look that way.
BeConverter and similar tools use a Vision-Language Model (VLM) to figure out the artistic “vibe” of an image. These models compare your photo against billions of data points to see where it fits mathematically. They can tell if a picture is a sharp 3D render or a soft oil painting. By 2026 standards, BeConverter makes this process incredibly fast, turning a piece of inspiration into a usable prompt string in just a few seconds.
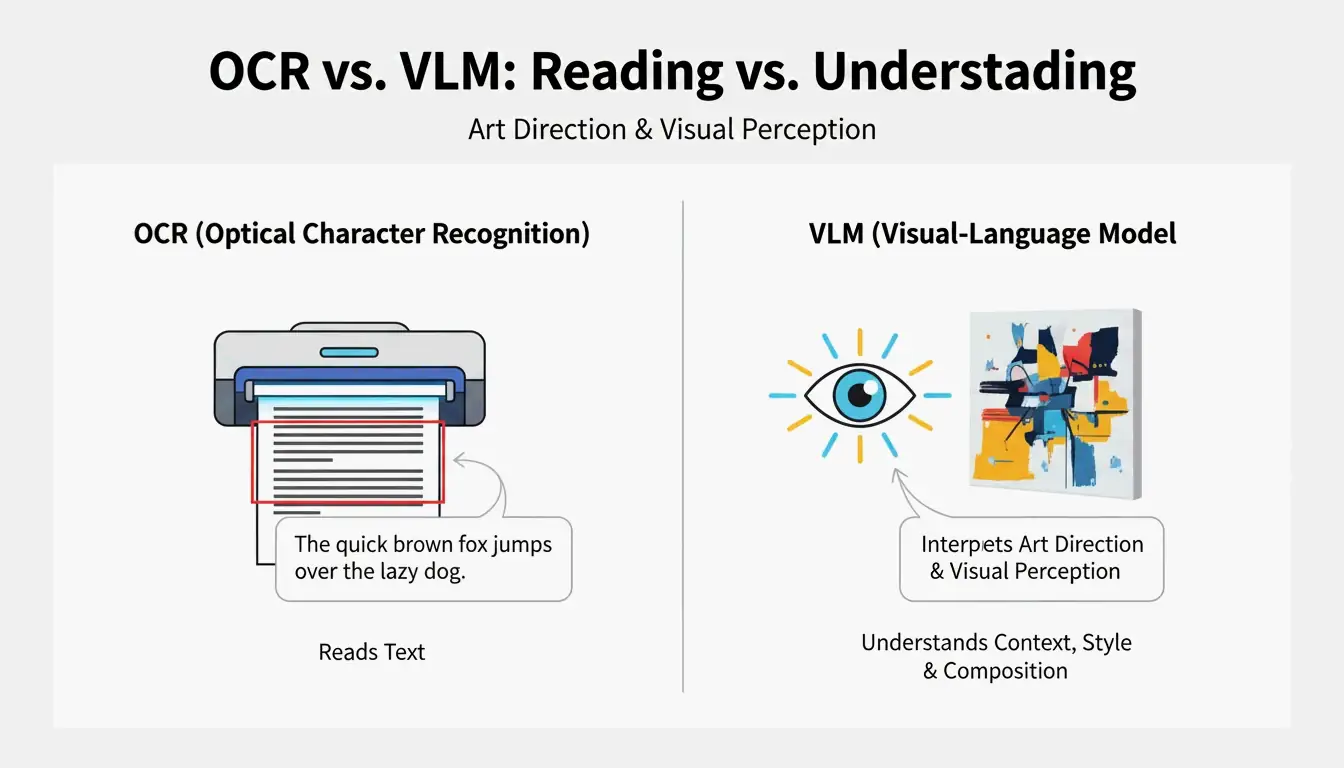
VLM vs. OCR: Why Typical Scanning Fails Art
Optical Character Recognition (OCR) is built to read letters and numbers, like the text on a document. As PromptsEra points out, while OCR can read the words on a receipt, a VLM reads the “art direction.” Instead of just seeing the word “STOP” on a sign, a VLM notices the octagonal shape, the faded red paint, the depth of field, and the angle of the sun—details that OCR completely misses.
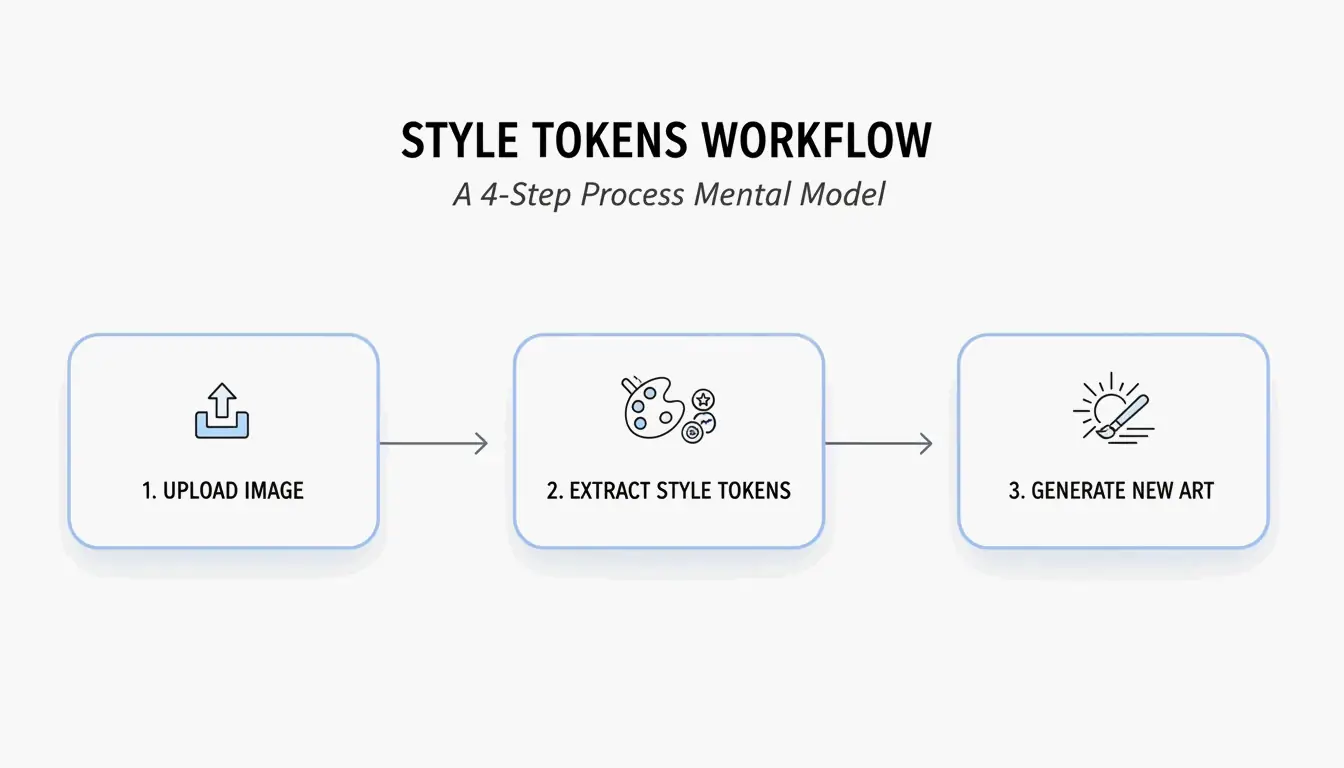
Step-by-Step: How to AI Prompt with BeConverter to Reverse Engineer Visuals
Reverse engineering works best when you have a system to pull out the most useful data. Based on the Style Token Isolation Strategy from PromptsEra, here is how you can recreate complex looks:
- Upload Your Source Image: Use a high-resolution file if possible. The VLM needs clear pixels to spot subtle details like “volumetric lighting” or the specific grain of a “35mm lens.”
- Pick Your Interrogator: Choose a mode that matches the AI you plan to use later. Pick CLIP Interrogator for descriptive, poetic prompts (best for Midjourney) or DeepDanbooru for a long list of tags (best for Stable Diffusion).
- Clean Up the Result: Once the VLM gives you a prompt, look for the Style Tokens. You’ll want to delete the original subject (like “a cat”) and keep only the style markers (like “cyberpunk, neon rim lighting, 8k”).
- Run it in Your Generator: Copy those cleaned-up tokens and paste them into Midjourney, Stable Diffusion, or FLUX.
Optimizing for 2026 Models: Adjusting for Claude 4.7 and GPT-5.5
By May 2026, LLMs like Claude 4.7 and GPT-5.5 have specific “personalities” for how they read prompts. Midjourney loves artistic descriptions, but FLUX needs you to be literal. According to PromptsEra, if your reverse prompt says “melancholy atmosphere,” you should change it for FLUX to something like “dark room with rain hitting the window.” This helps the model understand exactly where things should be in the scene.
The ‘Frankenstein’ Strategy: Merging Styles from Multiple Images
The most powerful way to use reverse engineering is the “Frankenstein” strategy—taking pieces from different images and stitching them together. You can use BeConverter to grab the lighting from “Image A” and the subject style from “Image B” to create something entirely new.
When you mix styles, keeping things consistent is key. You’ll need to manually set the Aspect Ratio (like adding --ar 16:9 for Midjourney) and remember to use Negative Prompts. Since reverse tools only see what is there, you have to tell the AI what not to include, such as “blurry” or “deformed” parts, to keep the quality high.
As Andrew Lo, Director of MIT’s Laboratory for Financial Engineering, suggests: “Always ask the LLM, what are you uncertain about? What information are you missing?” This can help you find the “blind spots” in the prompt you’ve reconstructed.
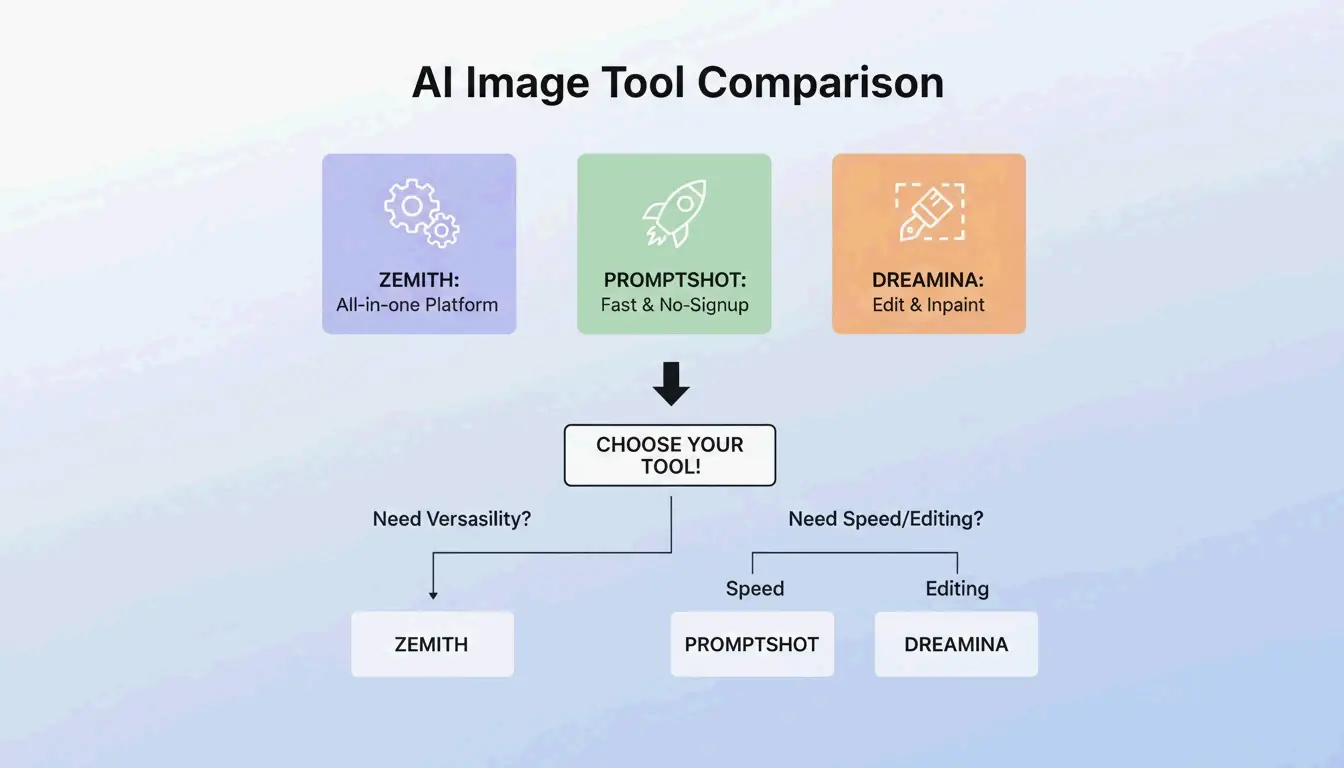
BeConverter vs. Zemith vs. PromptShot: Which Tool Wins in 2026?
The best tool for you in 2026 depends on how you work:
- Zemith: A major player with over 30,000 users as of 2026. According to Zemith, it’s popular because it’s an “all-in-one” platform, giving you 100 daily credits and working with over 25 models, including GPT-5.5.
- PromptShot AI: This is the go-to for quick extractions without needing to sign up. PromptShot AI focuses on a 5-step process designed for creators who need to “recreate and improve” AI art on the fly.
- Dreamina (GPT Image 2): Great for people who want to generate and edit in the same window. According to Dailyhunt, the GPT Image 2 model inside Dreamina lets you do “inpainting” and fix lighting right after the prompt is built.
Conclusion
Reverse engineering visuals with BeConverter is the fastest way to turn an inspiring image into a working AI prompt. By using VLMs to extract the “source code” of a style, you stop guessing and start getting professional results across different platforms. To start, just upload a reference photo to BeConverter, pick out the lighting and composition tokens, and try them out in Midjourney v7 or FLUX to see how the AI interprets your vision.
FAQ
Can reverse prompting identify the exact original prompt used by another creator?
No, it can’t read the original creator’s mind or see their exact keystrokes. It creates a descriptive guess based on what it sees in the image. Different models will prioritize different things, so it’s more of a reconstruction than a way to find hidden metadata.
Does image-to-prompt technology work on real smartphone photographs?
Yes, it’s actually very good at identifying real-world details like “golden hour” sun or specific camera lenses. PromptsEra notes that it can translate real textures into prompts, so you can “AI-ify” your own photos into different artistic styles.
Is it legal or ethical to use prompts extracted from copyrighted artwork?
Prompts are usually just short strings of text and aren’t typically covered by copyright. The ethical way to use this tech is to extract “Style Tokens” to help you create your own original work. As PromptsEra points out, using prompts to try and copy a protected character exactly can get into legal trouble, so it’s better to use these tools to learn new techniques and styles.
SectoJoy
• Indie Hacker & DeveloperI'm an indie hacker building iOS and web applications, with a focus on creating practical SaaS products. I specialize in AI SEO, constantly exploring how intelligent technologies can drive sustainable growth and efficiency.